
Machine Learning (ML) has transitioned from a niche academic pursuit to the operating system of the modern economy. Yet, a critical misunderstanding persists in 2026: treating Generative AI and Large Language Models (LLMs) as separate entities from Machine Learning.
This guide corrects that narrative. We frame Generative AI correctly as a subset of Deep Learning, which is a subset of Machine Learning. Whether you are a software engineer looking to integrate LLMs into workflows, or a manager conducting a cost-benefit analysis, this pillar page bridges the gap between the mathematical theory (Gradient Descent) and production reality (MLOps).
What is Machine Learning?
At its core, Machine Learning is a field of computer science that gives computers the ability to learn without being explicitly programmed. This definition, popularized by Arthur Samuel in 1959, remains the bedrock of the industry.
Unlike traditional software engineering, where a human writes specific rules to process data (if x > 5 then y), Machine Learning reverses the workflow. You provide the system with data and the desired answers, and the algorithm generates the rules.
The Hierarchy of AI (Where GenAI Fits)
To understand modern ML, you must visualize the hierarchy. Most confusion arises from separating these concentric circles:
- Artificial Intelligence (AI): The broad concept of smart machines.
- Machine Learning (ML): The subset of AI that learns from data (e.g., Scikit-learn algorithms).
- Deep Learning (DL): A specialized subset of ML using multi-layered Neural Networks (e.g., TensorFlow, PyTorch) to model complex patterns.
- Generative AI (GenAI): A subset of Deep Learning focused on creating new data (text, images) rather than just classifying existing data. Large Language Models (LLMs) live here.
SME Insight: “Stop treating LLMs like magic. They are probabilistic engines built on the same foundations Linear Algebra and Calculus as the spam filters from the early 2000s.” — Internal Lab Note, 2025.
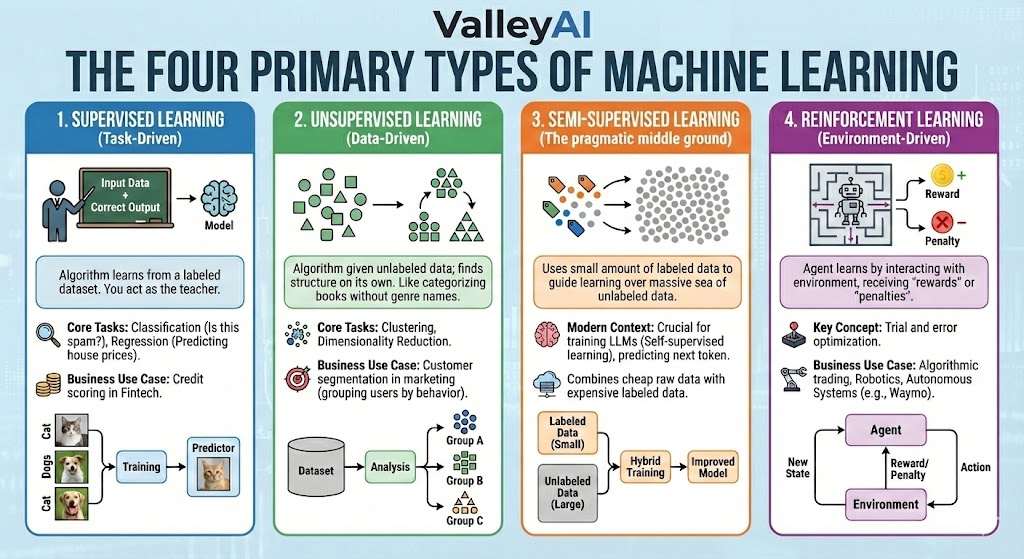
The Four Primary Types of Machine Learning
Understanding the type of learning required is the first step in the Machine Learning lifecycle.
1. Supervised Learning (Task-Driven)
This is the most common form of ML in business. The algorithm learns from a labeled dataset. You act as the teacher, providing the model with input data and the correct output.
- Core Tasks: Classification (Is this spam?), Regression (Predicting house prices).
- Business Use Case: Credit scoring in Fintech.
2. Unsupervised Learning (Data-Driven)
The algorithm is given unlabeled data and must find structure on its own. It is akin to a student learning to categorize library books without knowing the genre names.
- Core Tasks: Clustering, Dimensionality Reduction.
- Business Use Case: Customer segmentation in marketing (grouping users by behavior without pre-defined groups).
3. Semi-Supervised Learning
The pragmatic middle ground. Labeling data is expensive; raw data is cheap. This approach uses a small amount of labeled data to guide the learning process over a massive sea of unlabeled data.
- Modern Context: This is crucial for training LLMs (Self-supervised learning), where models predict the next token based on billions of internet text examples.
4. Reinforcement Learning (Environment-Driven)
The agent learns by interacting with an environment, receiving “rewards” for correct actions and “penalties” for mistakes.
- Key Concept: Trial and error optimization.
- Business Use Case: Algorithmic trading, Robotics, and Autonomous Systems (e.g., Waymo).
Comparison Matrix: Choosing the Right Approach
| ML Type | Data Requirement | key Algorithm Examples | Best For |
|---|---|---|---|
| Supervised | Labeled (Expensive) | Linear Regression, Random Forest | Predictive maintenance, Fraud detection |
| Unsupervised | Unlabeled (Cheap) | K-Means, PCA | Anomaly detection, Recommendation engines |
| Reinforcement | Environment/Simulation | Q-Learning, PPO | Dynamic pricing, Robotics control |
Essential Machine Learning Concepts
This section bridges ML theory to code implementation. To move from a manager to a practitioner, you must grasp these components.
1. The Dataset
Data is the fuel. In modern workflows, this includes Feature Engineering Best Practices transforming raw data into a format understandable by algorithms.
- Training Set: Used to teach the model (usually 70-80%).
- Test Set: Kept hidden during training to evaluate performance (20-30%).
2. The Math: Gradient Descent and Backpropagation
How do machines actually learn?
- Gradient Descent: Imagine standing on a mountain blindfolded. You feel the slope under your feet and take small steps downhill to find the lowest point (minimum error).
- Backpropagation: Popularized by Geoffrey Hinton, this is the algorithm used in Neural Networks to calculate the gradient. It propagates the error backward through the network to update the weights.
3. The Architecture: Transformers & Neural Networks
While Classical ML uses decision trees, modern AI relies on Neural Network Architectures.
- Transformers: The architecture behind ChatGPT and Claude. It utilizes a mechanism called self-attention to weigh the importance of different words in a sentence, regardless of their distance from one another.
4. Code Implementation: The Bridge
Below is a Python snippet demonstrating a basic Supervised Learning workflow using Scikit-learn. This represents the standard “Hello World” for software engineers entering ML.
# The "Bridge": From Logic to Code
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 1. Simulate Data (Business Logic: Customer features -> Churn risk)
# Features: [Usage Hours, Contract Length, Support Tickets]
X = np.array([[120, 1, 5], [50, 12, 0], [100, 2, 2], [20, 24, 0]])
# Labels: 1 = Churn, 0 = Stay
y = np.array([1, 0, 1, 0])
# 2. Split Data (Preventing Overfitting)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 3. Initialize & Train Model (The "Learning" Phase)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 4. Predict & Evaluate
predictions = model.predict(X_test)
print(f"Model Prediction: {predictions}")
# Output: Predicts customer behavior based on learned patternsReal-World Applications of ML
The value of ML is not in the model, but in the deployment.
1. Healthcare: Beyond Diagnostics
ML is moving from simple image recognition (reading X-rays) to predictive triage.
- Case: Predicting sepsis in ICU patients 6 hours before symptoms appear.
- Tech: Recurrent Neural Networks (RNNs) analyzing time-series vitals.
2. Finance: Algorithmic Risk
- Fraud Detection: Anomaly detection algorithms scan millions of transactions per second to flag outliers.
- High-Frequency Trading: Reinforcement learning models that adapt to market volatility in microseconds.
3. Software Engineering: Integrating LLMs
The most pressing application in 2026 is integrating LLMs into existing ML workflows. This is often called Composite AI using a classical Random Forest model for tabular business data, while using an LLM (via Hugging Face API) to summarize the unstructured customer feedback associated with that data.
Strategic Framework: When conducting a cost-benefit analysis of machine learning models, Executives must ask: “Does the cost of inference (running the model) exceed the value of the prediction?” For GenAI, the answer is often yes; for Classical ML, it is usually no.
Tools and Frameworks for Implementation
Choosing the right stack is critical for scalability.
1. The Heavyweights: TensorFlow vs. PyTorch
- TensorFlow (Google): historically favored for high-scale production environments and mobile deployment (TFLite).
- PyTorch (Meta): The dominant force in research and Generative AI. Most modern LLMs and papers on ArXiv use PyTorch. It is more Pythonic and easier to debug.
2. The Standard Library: Scikit-learn
For classical ML (Regression, Clustering, Support Vector Machines), Scikit-learn is the industry standard. It requires less compute power than Deep Learning frameworks and is often the right choice for structured business data.
3. The Modern Ecosystem
- Hugging Face: The GitHub of ML. The central hub for pre-trained Transformer models.
- Jupyter Notebooks: The interactive IDE used for data exploration and visualization.
- NVIDIA CUDA: The hardware interface layer. You cannot discuss modern ML without acknowledging that NVIDIA GPUs provide the parallel processing power required for Deep Learning.
Challenges and Future Trends
As we move toward 2027, the challenges are shifting from How do we build it? to How do we control it?
1. The Data Bias and Ethics Crisis
Models trained on historical data inherit historical biases. Andrew Ng has emphasized the Data-Centric AI movement improving the data quality is now more impactful than tweaking the algorithm code.
2. Overfitting and Generalization
Overfitting occurs when a model memorizes the training data (including the noise) rather than learning the underlying pattern. It performs perfectly in the lab but fails in production.
- Solution: Regularization techniques and larger, more diverse datasets.
3. MLOps: The Deployment Bottleneck
It works on my machine is the death knell of ML projects. MLOps (Machine Learning Operations) is the discipline of automating the deployment, monitoring, and management of models in production.
- Trend: Automated retraining pipelines that detect Data Drift (when real-world data diverges from training data).
4. Future Trend: Agentic AI
We are moving from Chatbots to Agents. Instead of just generating text, ML models are being given tool access (browsers, code interpreters) to execute multi-step tasks autonomously.
Key Takeaways for the Practitioner
- Don’t start with Deep Learning. If a simple Logistic Regression solves the problem with 85% accuracy, start there. It is cheaper, faster, and explainable.
- GenAI is not a strategy; it’s a tool. Use LLMs for unstructured data (text/images) and Classical ML for structured data (Excel/SQL).
- Respect the math. You don’t need a Ph.D., but understanding Gradient Descent helps you troubleshoot why a model isn’t converging.
- Prioritize Data Engineering. The best algorithm cannot fix broken data.
References & Further Reading:
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning.
- Vaswani et al. (2017). Attention Is All You Need (The Transformer Paper).
- Journal of Machine Learning Research (JMLR).
Kaleem
My name is Kaleem and i am a computer science graduate with 5+ years of experience in Computer science, AI, tech, and web innovation. I founded ValleyAI.net to simplify AI, internet, and computer topics also focus on building useful utility tools. My clear, hands-on content is trusted by 5K+ monthly readers worldwide.